如何快速"摸"他人博客的表情包
前言
每当看到别人博客好看的表情包很想要却不知道如何下手?
这篇博文教你如何快速把别人博客的表情包“摸”过来(doge
注:需要你的博客评论系统支持OwO格式的表情包
本次使用的是博客程序是Hexo,评论程序是Artalk
准备
- 一个支持开发者工具的浏览器
- IDM下载器(把表情保存到自己的博客肯定比第三方地址稳定)
- VSCode(当然如果你有更方便的工具也行)
- 脑子和手
开始
首先我们找到你想要“摸”的博客页面
打开开发者工具(快捷键F12)
选择“网络”选项卡,然后手动再刷新一下页面,以此捕捉网页全部资源
这时我们在筛选器里填写 .json 筛选出json文件
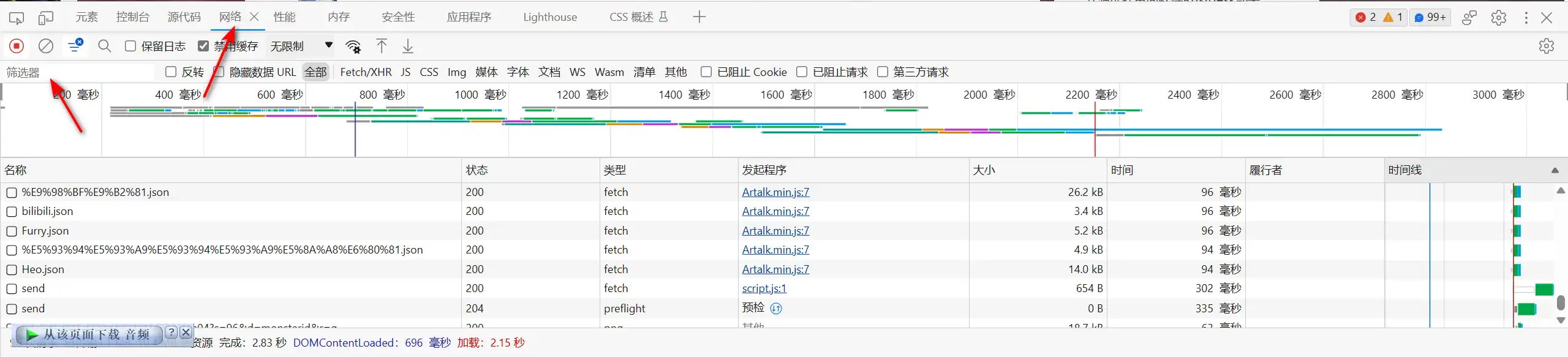
双击json文件
表情包的json结构大致应该为以下结构
1 | {"XXX": { |
或者artalk的表情包的结构也行(其他评论系统不一定能用)
1 | { |
目前我博客这两种结构的json都可以
得到json了我们就要开始把表情包下载下来了
我们这里用Python直接输出地址(不可能手动点吧)
把json保存到本地
下面是为懒人准备的代码
1 | import json |
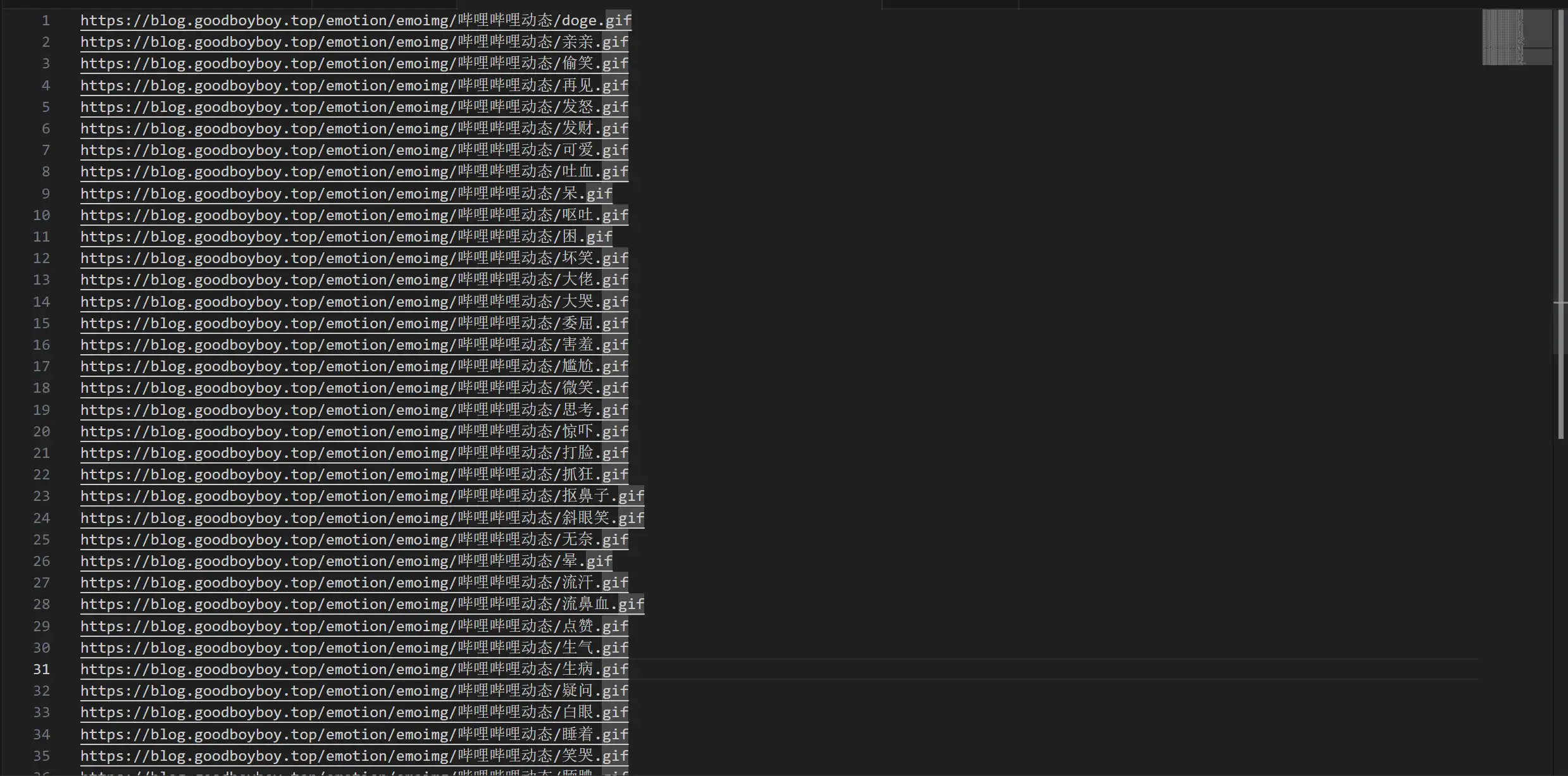
然后将输出的地址复制到另一个地方准备转码
如果你是第一种结构包含"img"等多余字符,使用VSCode替换成空白即可(总之需要一列干净的地址)
因为部分表情包是中文,idm无法正常下载带有中文路径的文件,所以我们需要对地址进行转码
打开https://www.matools.com/code-convert
将纯净的地址复制进去,取消勾选“转义分隔符”,然后点击“编码”
接着我们将得到的地址复制进VScode,将两个地址中的“%0A”替换为“\n”(也就是换行)
注:记得打开“使用正则表达式”,不然“\n”无效
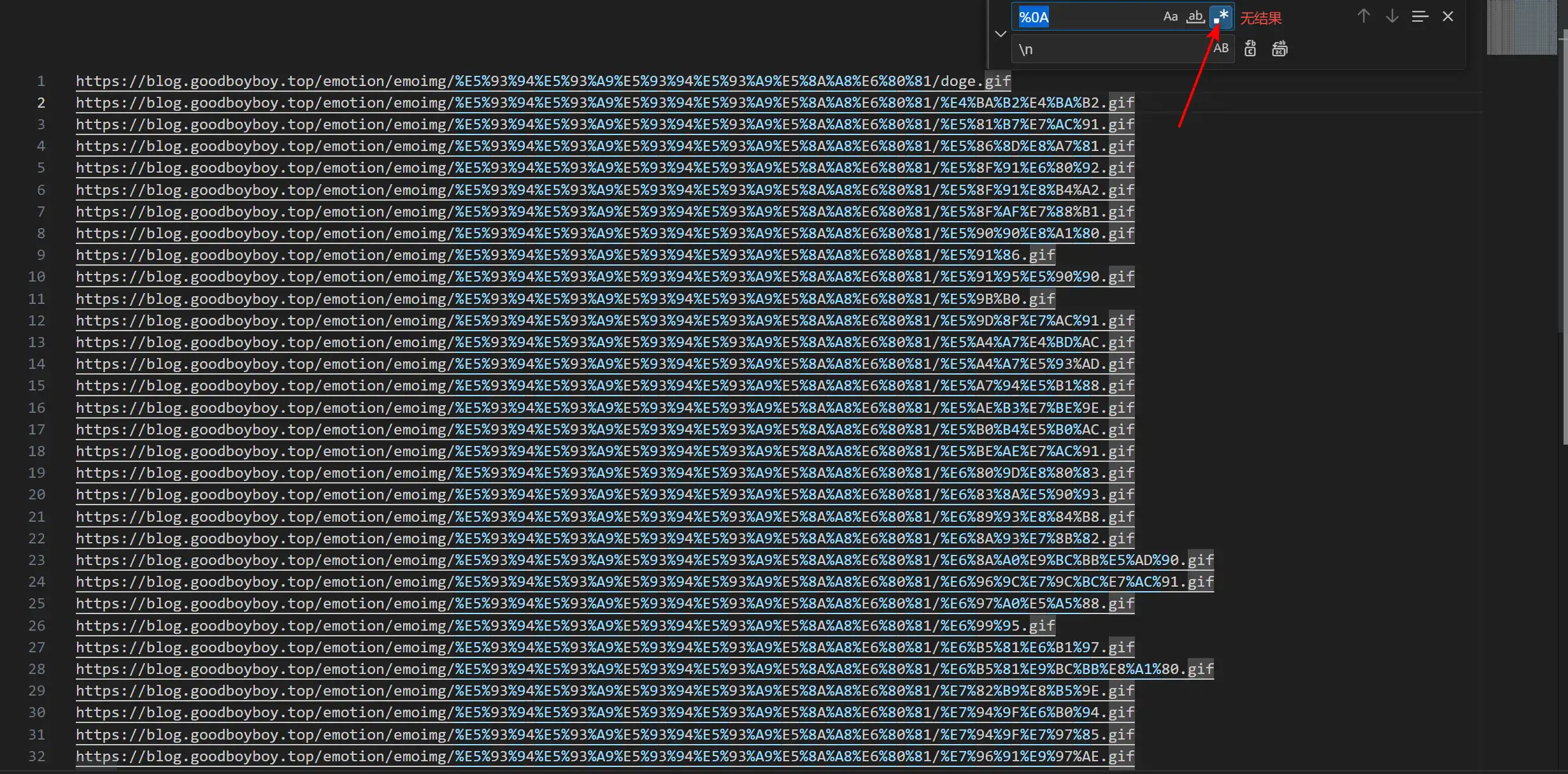
完成替换后我们将地址全部复制,打开IDM,点击“任务”>“从剪贴板中添加批量下载”
下载完最后在json文件中完成地址的替换即可😁

Use this card to join MyBlog and participate in a pleasant discussion together .
Welcome to GoodBoyboy 's Blog,wish you a nice day .



